

项目仓库: https://github.com/Akvicor/nginx-healthcheck-module
Nginx 自带的 upstream 失败处理主要依赖请求过程中的被动失败触发,例如连接失败、超时或上游返回错误后再调整 peer 状态。这种机制过于简单,当一个后端已经不可用时,流量可能仍然需要先打到它,Nginx 才能感知失败,而且就算后端一直不可用,一段时间后nginx也会自动将有问题的上游恢复,此时又会有用户访问到有问题的上游。
而 nginx-healthcheck-module 插件就是为了解决无法主动探测上游的问题,插件会在请求流量之外,主动周期性检查 upstream peer,并把不健康的 peer 标记为异常,并从负载均衡选择中跳过。
nginx-healthcheck-module 插件由 我 (Akvicor) 维护,修改自 yaoweibin/nginx_upstream_check_module,重点适配 Nginx 1.26+,并聚焦 TCP/UDP 健康检查。
当前维护版本支持
HTTP upstream 健康检查
Stream upstream 健康检查
TCP 检查
UDP 检查
HTML、CSV、JSON、Prometheus 状态输出
上游检查延迟统计
TCP 检查连接复用
它不再支持原项目里的 HTTP/FastCGI/MySQL/AJP/SSL hello 等七层检查类型
编译安装
首先你需要下载nginx的源码, 你可以从 GitHub 或 Nginx官网 上下载源码
项目仓库中有一个 build.sh 脚本, 里面有从nginx官方源码编译的方式, 你可以参照脚本内的方式编译出nginx的二进制可执行文件, 直接替换掉系统已安装的nginx的二进制可执行文件, 如果不知道当前系统的nginx命令文件的位置, 可以使用 which nginx 命令查询
当然也可以使用下面这个方式, 通过git库直接编译安装(下面这个configure中的参数并不全, 如果想要全部的默认参数看build.sh脚本)
git clone https://github.com/nginx/nginx.git
git clone https://github.com/Akvicor/nginx-healthcheck-module.git
cd nginx
git checkout release-1.26.3
git apply ../nginx-healthcheck-module/nginx_healthcheck_for_nginx_1.26+.patch
./auto/configure --with-stream --add-module=../nginx-healthcheck-module
make
make install补丁的作用是把健康检查结果接入 Nginx upstream peer 选择逻辑中。也就是说,模块不是只提供一个状态页面,而是真的会影响 round robin、hash、consistent hash、least_conn 等 upstream 负载均衡路径,让 down 状态的 peer 不再被选中。
完整配置示例
worker_processes 1;
error_log logs/error.log info;
events {
worker_connections 256;
}
http {
check_shm_size 2m;
server {
listen 8081;
location /health {
healthcheck_status;
}
location /status {
healthcheck_status json;
}
location /metrics {
healthcheck_status prometheus;
}
location / {
proxy_pass http://tcp-http-backends;
}
}
upstream tcp-http-backends {
server 127.0.0.1:8082;
server 127.0.0.2:8082;
check interval=3000 rise=2 fall=5 timeout=5000 default_down=true type=tcp;
}
}
stream {
check_shm_size 2m;
upstream tcp-cluster {
server 127.0.0.1:22;
server 192.168.0.2:22;
check interval=3000 rise=2 fall=5 timeout=5000 default_down=true type=tcp reuse=on;
check_keepalive_requests 10;
}
server {
listen 522;
proxy_pass tcp-cluster;
}
upstream udp-cluster {
server 127.0.0.1:53;
server 8.8.8.8:53;
check interval=3000 rise=2 fall=5 timeout=5000 default_down=true type=udp;
}
server {
listen 53 udp;
proxy_pass udp-cluster;
}
}最关键的是 upstream 里的 check 指令
check interval=3000 rise=2 fall=5 timeout=5000 default_down=true type=tcp;这表示每 3000ms 检查一次,单次检查超时为 5000ms。连续 2 次成功后标记为 up,连续 5 次失败后标记为 down。default_down=true 表示 Nginx 启动后 peer 默认先处于 down,等主动检查成功后再进入可用状态。
TCP 和 UDP 检查语义
TCP 检查会尝试连接 upstream peer。连接成功并且 socket 状态符合预期时,peer 被认为健康;连接失败、超时或 socket 错误会推动 fall 计数增长。
UDP 检查的语义和 TCP 不一样。UDP 没有连接建立过程,模块会发送一段默认 payload,通过接收路径检测 ICMP 错误。如果超时但没有收到 ICMP 错误,当前实现会按成功处理。这一点很重要:UDP 检查更适合发现明确的端口不可达等错误,不等价于完整的应用层协议检查。
TCP复用
默认情况下,TCP 检查连接不会复用。每次检查结束后,连接都会关闭。每一轮检查都会重新和上游建立 TCP 连接。
如果显式配置 reuse=on,模块会复用健康检查连接:
check interval=3000 rise=2 fall=5 timeout=1000 default_down=true type=tcp reuse=on;
check_keepalive_requests 10; # 非必须,省略这行插件会使用默认值10check_keepalive_requests 控制单条复用连接最多执行多少次检查,默认值是 10。达到次数后,连接会关闭并在后续检查中重新建立。
开启 reuse 后,需要理解一个行为差异:
第一次没有可复用连接时,模块会真正向上游发起 TCP connect。
后续复用同一条连接时,模块不再每轮新建 TCP 连接,而是在保存的 socket 上执行
recv(..., MSG_PEEK)。如果 socket 仍可读,或者返回
EAGAIN,模块认为这条内核维护的连接仍然健康。如果 peer 关闭连接、socket 出错、检查超时或达到复用次数,连接会被关闭,后续再重新建立。
因此reuse=on 更适合希望降低健康检查连接开销的场景(例如降低流量消耗)。它验证的是既有 TCP 连接是否仍然正常,而不是每个检查周期都验证“新建连接是否成功”。如果你希望每一轮都强制执行一次新的 TCP connect,就保持默认的 reuse=off。
当开启 TCP reuse 且 worker 数量大于 1 时,peer 会按 peer_index % worker_processes 分配给特定 worker 检查。这样可以把健康检查连接数量控制在接近 peer 数,而不是 peer 数 * worker_processes。
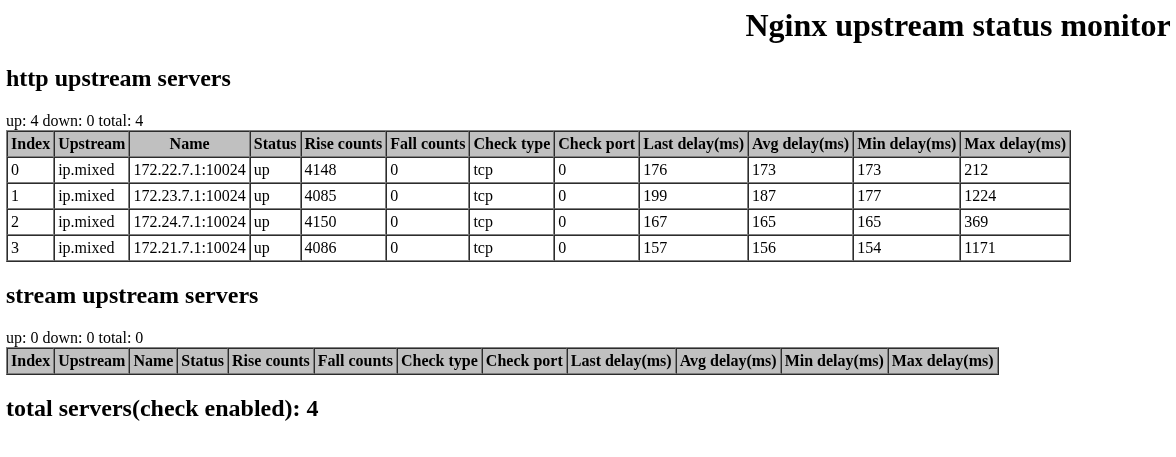
状态接口和延迟统计
模块提供 healthcheck_status 指令暴露状态接口:
location /status {
healthcheck_status;
}
location /json {
healthcheck_status json;
}
location /metrics {
healthcheck_status prometheus;
}也可以通过 query 参数切换格式:
/status?format=html
/status?format=csv
/status?format=json
/status?format=prometheus
/status?format=json&status=down
/status?format=json&status=upJSON 输出会按 http 和 stream 分类展示 peer 状态,典型字段包括:
{
"index": 0,
"upstream": "web_backends",
"name": "127.0.0.1:8081",
"status": "up",
"rise": 2,
"fall": 0,
"type": "tcp",
"port": 0,
"last_delay_ms": 1,
"avg_delay_ms": 1,
"min_delay_ms": 1,
"max_delay_ms": 2
}这里的延迟字段来自健康检查本身
last_delay_ms:最近一次成功检查耗时。avg_delay_ms:成功检查平均耗时。min_delay_ms:成功检查最小耗时。max_delay_ms:成功检查最大耗时。
这些字段对于排查后端抖动很有用。健康状态只告诉你 up 或 down,延迟统计可以进一步暴露“还能连上,但连接变慢”的问题。
Prometheus 输出则更适合接入监控系统,当前包含总数、up/down 数量、generation,以及每个 peer 的 rise、fall、active 指标。
配置建议
如果你是第一次接入,可以从保守配置开始:
check interval=3000 rise=2 fall=5 timeout=1000 default_down=true type=tcp;default_down=true更适合生产环境,避免 Nginx 启动后把尚未检查成功的后端直接纳入流量。rise不要设得太低,否则短暂成功可能导致不稳定后端过快回到流量路径。fall不要设得太低,否则偶发网络抖动可能导致后端频繁上下线。timeout应该小于业务可接受的失败等待时间。后端数量很多时,调大
check_shm_size。如果健康检查连接数压力明显,或者健康检查消耗流量过多,再考虑
type=tcp reuse=on。UDP 检查不要当作应用层协议健康检查,它只表达当前模块实现下的 UDP/socket 可达性判断。
已经编译好的nginx的debian源
增加的模块
nginx_upstream_check_module
ngx_http_geoip2_module
增加GPG密钥
curl -fsSL https://cdn.ksyaki.com/debian/nginx-team/public-key.asc \
| gpg --dearmor --batch --yes -o /usr/share/keyrings/akvicor.gpgdebian 13 源(Trixie)
tee /etc/apt/preferences.d/99-akvicor-nginx.pref >/dev/null <<'EOF'
Package: nginx nginx-* libnginx-mod-*
Pin: origin cdn.ksyaki.com
Pin-Priority: 1001
EOF
echo "deb [signed-by=/usr/share/keyrings/akvicor.gpg] https://cdn.ksyaki.com/debian/nginx-team trixie main" \
| tee /etc/apt/sources.list.d/akvicor-nginx.list
apt update
apt install nginxdebian 12 源(Bookworm)
tee /etc/apt/preferences.d/99-akvicor-nginx.pref >/dev/null <<'EOF'
Package: nginx nginx-* libnginx-mod-*
Pin: origin cdn.ksyaki.com
Pin-Priority: 1001
EOF
echo "deb [signed-by=/usr/share/keyrings/akvicor.gpg] https://cdn.ksyaki.com/debian/nginx-team bookworm main" \
| tee /etc/apt/sources.list.d/akvicor-nginx.list
apt update
apt install nginx